
K-Wav2vec 2.0: Automatic Speech Recognition based on Joint Decoding of Graphemes and Syllables
This article is review and derivation of Kim et al., K-Wav2vec 2.0: Automatic Speech Recognition based on Joint Decoding of Graphemes and Syllables
Introduction
In recent years, self-supervised methodology has shown success in various fields, including natural language processing, image recognition and auto speech recognition
The Wav2vec 2.0 model is an end-to-end framework of self-supervised learning of Automatic Speech Recognition(ASR), which is an effective pre-training method to learn speech representations
- When followed by fine-tuning with small amounts of labeled data, the Wav2vec2.0 model has shown remarkable performance in English ASR tasks
- It is still an open question whether this method can be effective with other language
In the Korean writing system, letters are written in syllabic blocks, where one sound is made at once
- This unique writing system allows us to build a Korean ASR model that is based on either graphemes(자소) or syllable(음절) blocks
- Graphemes: ㅇㅏㄴㄴㅕㅇㅎㅏㅅㅔㅇㅛ
- Syllable: 안녕하세요
- Most Korean ASR model were developed with syllables, and syllable-based models outperform grapheme-based models
- Grapheme require more combinations to predict(11172)
- However, syllable-based models also have data sparseness problem for infrequently used syllables and the Out-Of-Vocabulary(OOV) problem when the training data is insufficient
- OOV problem arises when syllables that do not appear in the training set appear in the test set
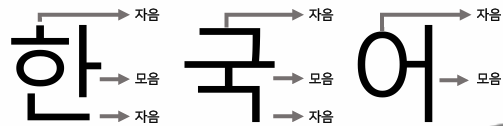
(Figure 1. Figure 1. Grapheme(자소) and syllables(음절) in korean)
To overcome these problem, using Multi-Task Learning(MTL) approach
- Sharing some representations from different tasks
- Chen et al., 2021
- By learning the shared representations between high-level and low-level modeling units, multi-task models alleviate data sparseness issues and achieve better performance
- Ueno et al., 2018
- Recovering methods to substitute OOV words produced for high-level decoding with segments generated in low-level outputs
- Propose a multi-task hierarchical fine-tuning architecture of Wav2Vec2.0 to reflect the unique relationship that exists in Korean writing between syllables and graphemes
- In the inference step, we used a joint decoding strategy that considers high-level and low-level units to find the best sequence from a set of candidates instead of using additional language models
- Additionally, we also experimented with the cross-lingual transfer of the English Wav2Vec2.0 pretrained model to Korean ASR tasks to overcome limited dataset
Background
The Wave2Vec 2.0 consists of three networks: a feature encoder, a contextual transformer, and a quantization module
- The feature encoder, which is composed of a multi-layer Convolutional Neural Network(CNN), encodes the raw audio 𝑋 and outputs the latent speech representation Z
- The contextual transformer, which is a stack of transformer encoders, learns the context representation 𝐶 by taking latent speech representation as input
Pre-training and fine-tuning of Wav2Vec2.0
- A certain portion of the latent representation 𝑍 are randomly masked
- Solving a contrastive task, distinguishing the true quantized vector
- Discrete latent vectors are randomly sampled from the other time steps
\(L_m = -\log{\frac{\exp(\frac{sim(c_t,q_{true})}{k})}{\sum_{q~Q_t} \exp (\frac{k}{sim(c_t,q)})}},\) where \(sim=\frac{a^Tb}{\mid\mid a\mid\mid\mid\mid b\mid\mid}\)
- In fine-tuning, randomly initialized linear layer is added
- Takes the contextualized representation and generate the words
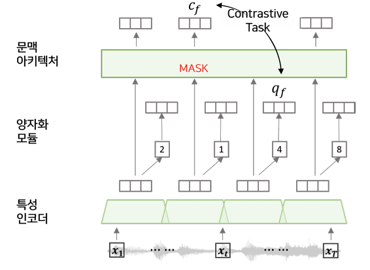
(Figure 2. Wave2Vec2.0 architecture)
Method
Multi-task hierarchical architecture
-
In the grapheme encoder, a linear layer and softmax is adopted to project the encoded features into a grapheme vocabulary $g\in G = (ㄱ,ㄴ,ㄷ,…,ㅏ,ㅑ,…), p(g_f\mid c_f)$
-
In the syllable encoder, a stack of transformer encoder is adopted for converting the encoded features to a sequence of hidden vector ℎ to capture the relationship between low-level and high-level information
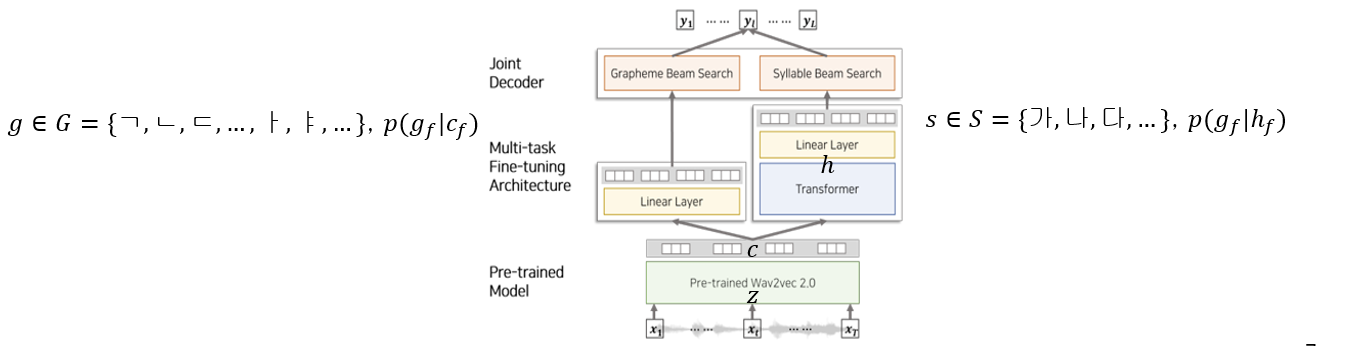
(Figure 3. Overview of proposed ASR framework)
We used the Connectionist Temporal Classification(CTC) loss when training the model
- The CTC is an approach for sequence labeling, wherein the lengths of the label sequence and the output frames are different
The objective function of the proposed architecture is the weighted sum of grapheme and syllable CTC losses to learn the two tasks simultaneously
- $L_{MTL} = \lambda \log p_{syll}^{ctc}(Y\mid X) + (1-\lambda) \log p_{graph}^{ctc}(Y\mid X)$
To leverage the ASR performance with limited data, we explore cross-lingual transfer by further English pre-training model with a Korean dataset
- We use pre-trained Wave2Vec2.0 with English dataset(960h)
- Additionally, we further pre-train this model on the Korean dataset(965h)
Joint Decoder
The join decoder combines low-level and high-level beam search results to find the best sequence within a limited amount of time
- We used the CTC beam search decoder, which decodes iteratively to find candidates over time-steps of CTC output and scores them with given probability of each time-step
- The objective of the joint decoder is to find the most probable sequence 𝑌 ̂ among the candidates
- $\hat {Y} = argmax_{\hat {Y} \in \hat{S} \cup\hat{G}} (\gamma p_{syll}^{ctc}(Y\mid X) + (1-\gamma)p_{grap}^{ctc}(Y\vert X ))$
- Non-overlapped candidates of the grapheme beam search exist $\hat G - (\hat S \cap \hat G)$, alleviating the OOV problem
- There isn’t ‘깄‘ in syllable, but grapheme can generate ‘깄’ via ㄱ+ㅣ+ㅆ
- In Wav2Letter, KenLM was utilized for beam searching
Datasets
Ksponspeech
Open-domain dialog corpus recorded with 2000 native Korean speakers in a controlled, quiet environment setting
- 965h of training, 4h of development, 3h of evaluation-clean, 4h of evaluation-other
ClovaCall
Custom-service dialog corpus recorded by 11000 people via phone calls
Insufficient training data to cover the vocabulary of the evaluation set, causing OOV problems
50h of training and 1h of testing
(Table 1. OOV with each modeling unit in the evaluation sets)
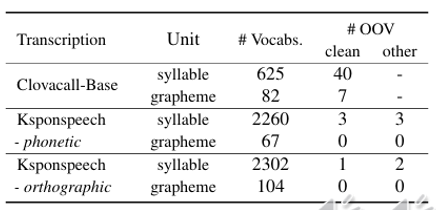

(Figure 7. phonetic and orthographic)
Training
Pre-trained model
- We pre-trained Wav2Vec2.0 model with 960h of English LibriSpeech dataset, followed by 950h of Korean KsponSpeech dataset
- For stable pre-training, we used silence elimination, excluding any ranges under 30dB in raw audio
Fine-tuning strategies
- Syllable encoder is a stack of 2 transformer blocks with 768 dimension and 8 heads and a linear layer
- For Clovacall, we froze the parameters of pre-trained parts for first 10k updates
- For Ksponspeech, initial freezing was not adopted
- We chose the checkpoint having the lowest Word Error Rate(WER)
Evaluation
Grapheme outputs are converted to syllables before evaluation for fair comparison
- ㅇㅏㄴㄴㅕㅇ => 안녕
Character Error Rate(CER)
- Levenshtein distance between the actual sequence of transcription and predicted sequence
WER
- Levenshtein distance with word level
Space-normalized WER(sWER)
- WER used to evaluate Korean ASR
60 beam size
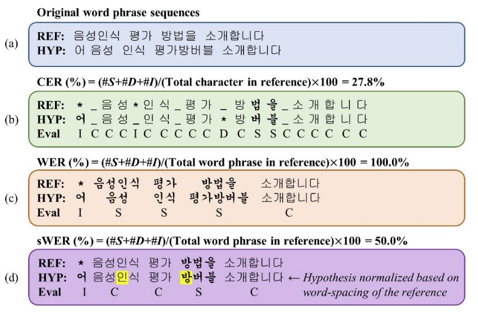
(Figure 8. Comparison between CER, WER and sWER. C,S,I and D denote the correct, substituted, inserted, and deleted words, respectively(1))
(1) Jeong-Uk Bang et al., KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition. Applied Sciences. 2020. https://doi.org/10.3390/app10196936
Experimental Results
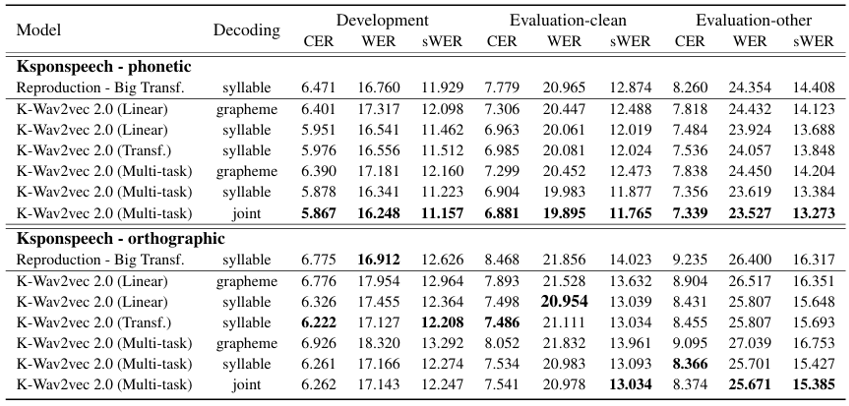
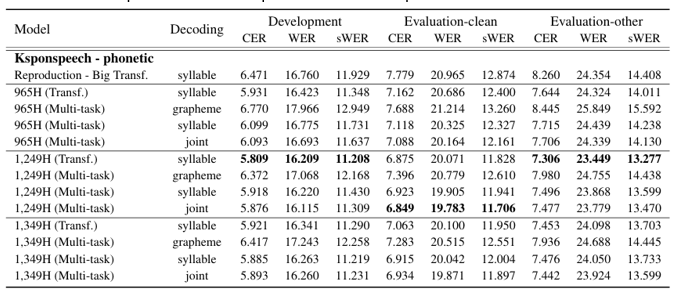
High-resource evaluation(KsponSpeech)
Syllable-based, multi-task fine-tuning, and joint decoder seemed to improve the Korean ASR
Orthographic has additional character, leading models to confuse to learn the distribution
(Table 2. Evaluation results on Ksponspeech development/evaluation-clean/evaluation-other sets with dual transcription)
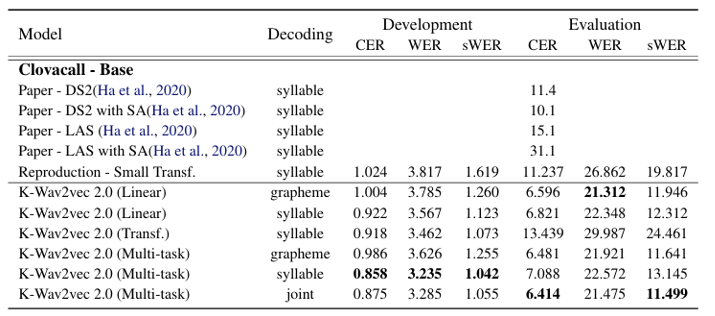
Low-resource evaluation(Clovacall)
Further pre-training with unlabeled data leads the model to better effective to fine-tuning with small data
For the evaluation set, the syllable beam search was assisted by the grapheme beam search to generate the correct OOVs
(Table 3. Table 3. Evaluation results on Clovacall, where the amount of training data is limited)
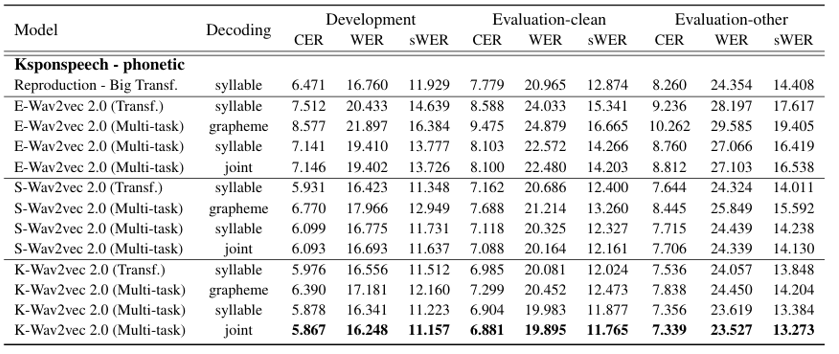
Further pre-training evaluation
We pre-trained on KsponSpeech training data from the initial state to obtain S-Wav2vec2.0
E-Wav2vec2.0 was pre-trained on Librispeech(English) training data
Proposed pre-training models clearly outperformed the others
(Table 4. Results of different pre-training methods with the Ksponspeech phonetic transcription)
Appropriate data for pre-training
VOTE400 has unique speech patterns of elderly people, making model disturb the performance
(Table 5. Description of Korean speech datasets in public)
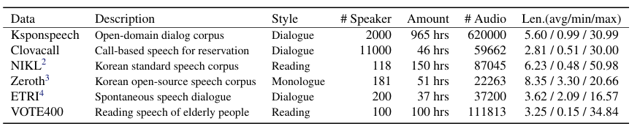
(Table 6. Description of Korean speech datasets in public. 965H is Ksponspeech, 1249H is 965H+Clovacall+NIKL+Zeroth+ETRI, and 1349H is 1249H+VOTE400)
Discussions
Intermediate relations in multi-task model
- We observed that attention was activated in the region where it was pronounced
- Attention is mostly activated around the target grapheme to gather relational information of the syllable
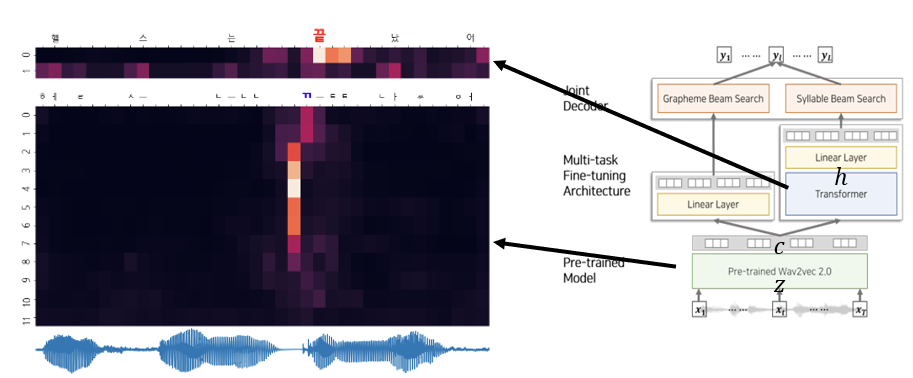
(Figure 9. Visualization of attention maps generated from the multitask model. In the middle of the figure, attentions are activated to relevant target grapheme highlighted blue. Attention maps of relational information between graphemes and target syllable are shown on the top.)
Analysis of contribution weight in joint decoder
Joint decoding with 𝜆=0.5 yielded the best performance in terms of WER and sWER on the Ksponspeech
Clovacall had insufficient training data, the model overfitted and generated highly confident outputs on the development set
- The grapheme decoder did not have many opportunities to correct the possible errors
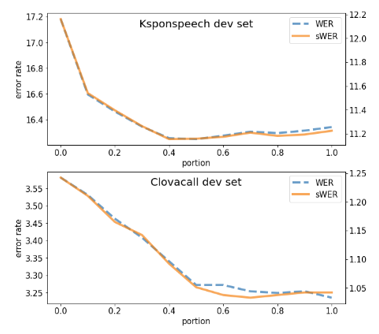
(Figure 10. Error rates on the development set with different contribution weights in joint decoding)
Alleviating OOV problem with joint decoder
We investigate whether the joint decoder can help alleviate the OOV problem on the Clovacall test set with 𝛾=0.5
The beam search result of grapheme utilized in the joint decoding process alleviated the OOV problem when syllable decoding produced unconfident results for OOV syllables in speech
The restoration property of the joint decoder can play an important role in a service level ASR system
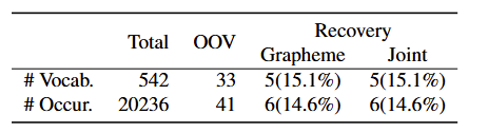
(Table 7. Results of OOV syllables recovery on the Clovacall test set, varying the decoding strategy. OOV indicates out-of vocabulary syllables possible to construct with grapheme vocabulary.)
Cross-lingual transfer in further pre-training
Because initialized states of the English models are useful, the additional pre-training method began with a lower validation loss than the from-scratch model
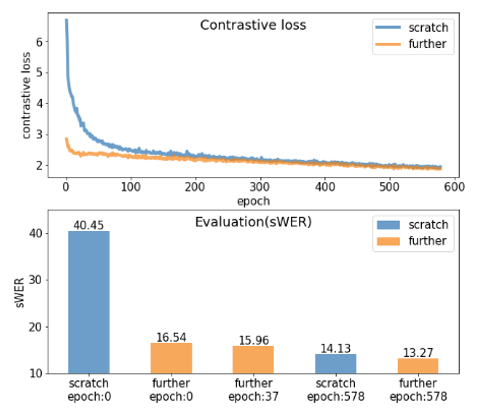
(Figure 11. Contrastive loss and evaluation results with different pretraining methods)
Conclusion
We first presented a multi-task fine-tuning architecture with a joint decoder and a further pre-training approach for the Korean ASR system
Multi-task model can generate multi-level outputs without performance degeneration, and our joint decoder enhances the ASR performance by overcoming the drawbacks of each modeling unit
Our system achieved the best performance in terms of sWER on both phonetic and orthographic transcription and alleviated the OOV problems
Future work should include evaluating the proposed architecture with models further pre-trained until contrastive loss is no longer small
- Future research should include the development of a decoding strategy that uses acoustic and linguistic information together
Appendix
CTC
Given a ground truth label sequence $Y=y_1,…,y_n$, the CTC process can expand $Y$ to a set of sequences $\Omega(Y)$ by adding a blank token between consecutive labels and allowing each label to be repeated
Posterior conditional probability of label sequence with the CTC process is computed as follows
- $p_{syll}^{ctc}=\sum_{l\in\Omega (Y)}(l\mid X)=\sum_{l\in\Omega (Y)}\prod p(s_f \mid h_f)$
- $p_{syll}(Y=s_1,…,s_f \mid X) = \prod p(s_f\mid h_f)$
- $p_{grap}(Y=g_1,…,g_f \mid X) = \prod p(g_f\mid h_f)$

(Figure 12. CTC loss)

(Figure 13. CTC alignments)

(Figure 14. CTC loss)

댓글남기기